-
Bus Reminder Bubble
-

-

-

-

-

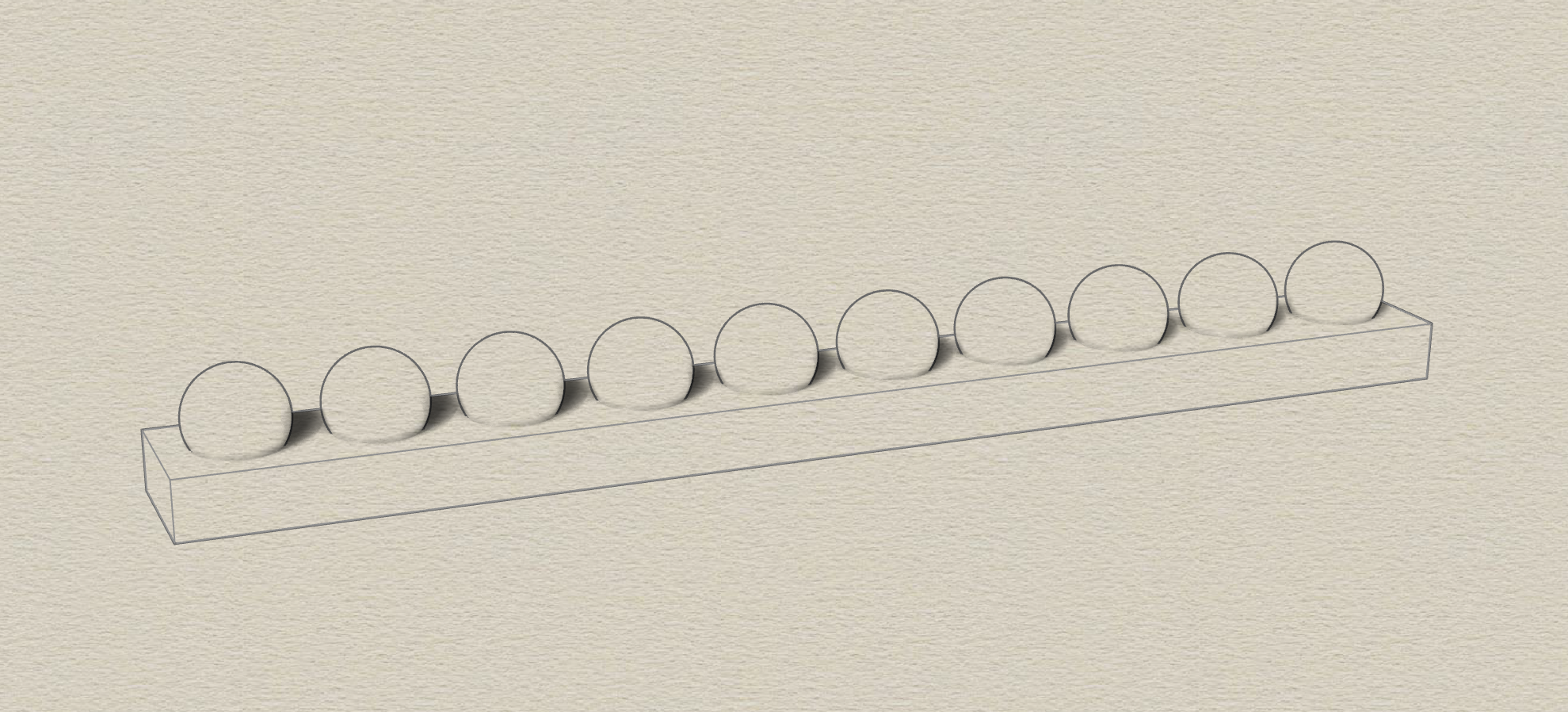
This project is an classical style Bus Reminder. It can showcase all or selected bus at the specific stop by LED bubble. When a bus is going to come to the bus stop, the LED bubble which represents it will be lighted up. Every bubble represents a coming bus in its 5 min time span.
Problem Statement:
Get a clear picture is important in every bustling morning for lazy guys like my girlfriend and me. In cold winter, I do neither like to go to the bus stop too early and wait in cold weather nor like to go to the bus stop too late and miss the bus. Therefore, I was thinking, if there is something that can vividly tell me when next bus and next next bus will come and enable me to (maximize my bed-time) know when I should get off the bed and go out for catching the bus.
Goal:
In this project, I'm going to make a classical style Bus Reminder. It will showcase (all or selected) bus at the specific stop by LED bubble.
When a bus is going to come to the bus stop, the LED bubble which represents it will be lighted up. Every bubble represents a coming bus in its 6 min time span. For example, if a 61C bus is going to come to the stop in 16 mins, the 3rd bubble (from the left) will be lighted up. And, if another 61D bus is going to come in 25 mins, the 5th bubble will also be lighted up.
This device provides me with a comprehensive, intuitive and glanceable approach to know the status of coming bus.
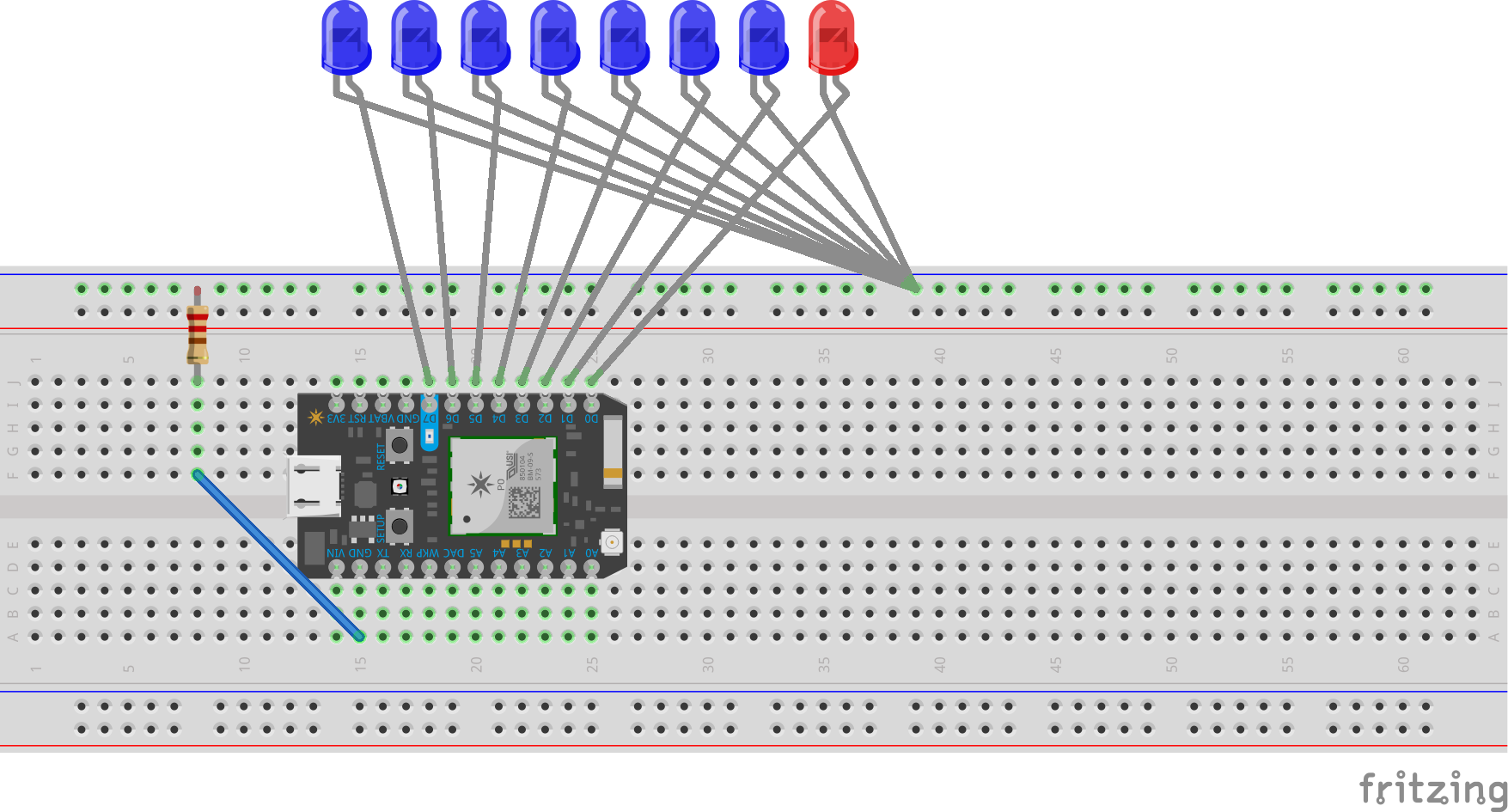
Bill of Parts:
1x Particle Photon
8x LEDs (1x Red, 7x Blue)
8x Ping Pong Balls (White)
Make Process
// This #include statement was automatically added by the Particle IDE.
#include "JsonParserGeneratorRK.h"
JsonParser parser;
int led1 = D0;
// setup() runs once, when the device is first turned on.
void setup() {
// Put initialization like pinMode and begin functions here.
ledrun(8,led1);
}
void getPAdata(){
String sData = String(10);
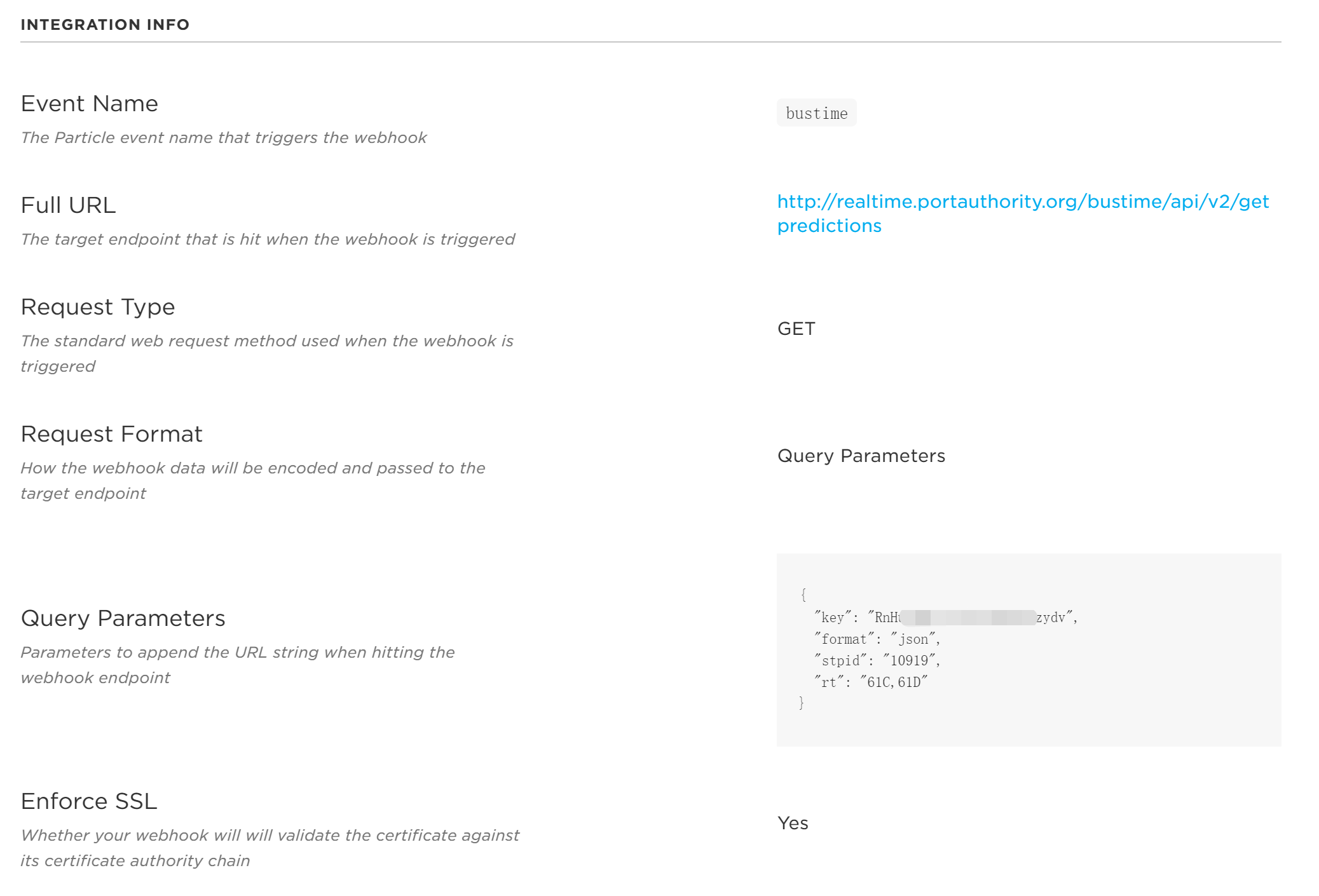
Particle.publish("bustime",sData,PRIVATE); //trigger the WEBHOOK
Particle.subscribe("hook-response/bustime", myHandler, MY_DEVICES); //get response
}
bool* makeLedPattern(int numberled, int interv, int val){ //generate a led pattern array
bool* ledPattern;
ledPattern = new bool[numberled];
for (int i =0; i < sizeof(ledPattern); i++){ // fill array with false
ledPattern[i] = false;
}
if (val > 0){ //if val > 0, generate a meaningful pattern; else generate an empty pattern
int nled = val/interv;
if (nled < numberled){
ledPattern[nled] = true;
}
}
return ledPattern;
}
bool* sumLedPattern(bool* first, bool* second){ //overlap two led pattern
for (int i = 0; i< sizeof(first); i++){
if (first[i] == true || second[i] == true){
first[i] = true;
}
}
return first;
}
void processLed(bool* Pattern, int sLedPin){ //pull led on in pattern; Pattern = the led pattern; sLedPin = the first led pin
for (int i = 0; i< sizeof(Pattern); i++ ){
pinMode(sLedPin+i,OUTPUT);
if (Pattern[i] == true){
digitalWrite(sLedPin+i,HIGH);
} else {
digitalWrite(sLedPin+i,LOW);
}
}
}
void processData() {
//Particle.publish("showbustime",printJson(jsdata),PRIVATE);
int nBus = parser.getReference().key("bustime-response").key("prd").size();
String snBus = String (nBus);
snBus = "Number of Bus:"+snBus;
Particle.publish("debugbustime",snBus,PRIVATE);
//delay(300);
bool* resltLedPattern;
resltLedPattern = makeLedPattern(8,5,-1); // generated an emplty pattern;
if (nBus > 0) { // when number of bus > 0
for(int i = 0; i < nBus; i++){
String rtBus = parser.getReference().key("bustime-response").key("prd").index(i).key("rt").valueString();
int prdctdnBus = parser.getReference().key("bustime-response").key("prd").index(i).key("prdctdn").valueInt();
Particle.publish("showbustime","rtBus:"+rtBus+"; prdBus:"+String(prdctdnBus)+";",PRIVATE);
bool* businfo; //generate pattern bus by bus
businfo = makeLedPattern(8,5,prdctdnBus);
resltLedPattern = sumLedPattern(resltLedPattern,businfo); //overlay all pattern
// delay(300);
}
}
processLed(resltLedPattern,led1); //light LED
}
void myHandler(const char *event, const char *data) {
// Handle the integration response
int responseIndex = 0;
// Particle.publish("debugbustime","Event Name: "+String(event),PRIVATE);
String sevent = String(event);
String sresponseIndex = sevent.substring(sevent.lastIndexOf("/")+1);
responseIndex = sresponseIndex.toInt();
// Particle.publish("debugbustime","Current Chunk Number: "+String(responseIndex),PRIVATE);
if (responseIndex == 0) {
parser.clear();
}
parser.addString(data);
if (parser.parse()) {
// Looks valid (we received all parts)
// This printing thing is just for testing purposes, you should use the commands to
// process data
Particle.publish("debugbustime","Total Chunk Number: "+String(responseIndex+1),PRIVATE);
processData();
}
}
void ledrun(int numLeds, int sLed){ //for led test
for(int i=0;i<numLeds;i++){
pinMode(sLed+i, OUTPUT);
digitalWrite(sLed+i,HIGH);
delay(150);
digitalWrite(sLed+i,LOW);
}
}
// loop() runs over and over again, as quickly as it can execute.
void loop() {
getPAdata();
delay(1*60*1000); //refresh data per 3 min
// ledrun();
// The core of your code will likely live here.
}Next is the JsonParserGeneratorRK package which is used to process the JSON response from WEBHOOK.
Full detail of JsonParserGeneratorRK can be found at github page:
//file name: JsonParserGeneratorRK.h
#ifndef __JSONPARSERGENERATORRK_H
#define __JSONPARSERGENERATORRK_H
#include "Particle.h"
// You can mostly ignore the stuff in this namespace block. It's part of the jsmn library
// that's used internally and you can mostly ignore. The actual API is the JsonParser C++ object
// below.
namespace JsonParserGeneratorRK {
// begin jsmn.h
// https://github.com/zserge/jsmn
/**
* JSON type identifier. Basic types are:
* o Object
* o Array
* o String
* o Other primitive: number, boolean (true/false) or null
*/
typedef enum {
JSMN_UNDEFINED = 0,
JSMN_OBJECT = 1,
JSMN_ARRAY = 2,
JSMN_STRING = 3,
JSMN_PRIMITIVE = 4
} jsmntype_t;
enum jsmnerr {
/* Not enough tokens were provided */
JSMN_ERROR_NOMEM = -1,
/* Invalid character inside JSON string */
JSMN_ERROR_INVAL = -2,
/* The string is not a full JSON packet, more bytes expected */
JSMN_ERROR_PART = -3
};
/**
* JSON token description.
* type type (object, array, string etc.)
* start start position in JSON data string
* end end position in JSON data string
*/
typedef struct {
jsmntype_t type;
int start;
int end;
int size;
#ifdef JSMN_PARENT_LINKS
int parent;
#endif
} jsmntok_t;
/**
* JSON parser. Contains an array of token blocks available. Also stores
* the string being parsed now and current position in that string
*/
typedef struct {
unsigned int pos; /* offset in the JSON string */
unsigned int toknext; /* next token to allocate */
int toksuper; /* superior token node, e.g parent object or array */
} jsmn_parser;
/**
* Create JSON parser over an array of tokens
*/
void jsmn_init(jsmn_parser *parser);
/**
* Run JSON parser. It parses a JSON data string into and array of tokens, each describing
* a single JSON object.
*/
int jsmn_parse(jsmn_parser *parser, const char *js, size_t len,
jsmntok_t *tokens, unsigned int num_tokens);
// end jsmn.h
}
/**
* Class used internally for writing to strings. This is a wrapper around either
* String (the Wiring version) or a buffer and length. This allows writing to a static buffer
* with no dynamic memory allocation at all.
*
* One of the things about String is that while you can pre-allocate reserve space for data,
* you can't get access to the internal length field, so you can't write to raw bytes then resize
* it to the correct size. This wrapper is that allows appending to either a String or buffer
* to get around this limitation of String.
*
* You can also use it for sizing only by passing NULL for buf.
*/
class JsonParserString {
public:
JsonParserString(String *str);
JsonParserString(char *buf, size_t bufLen);
void append(char ch);
size_t getLength() const { return length; }
protected:
String *str;
char *buf;
size_t bufLen;
size_t length;
};
/**
* Base class for managing a static or dynamic buffer, used by both JsonParser and JsonWriter
*/
class JsonBuffer {
public:
JsonBuffer();
virtual ~JsonBuffer();
JsonBuffer(char *buffer, size_t bufferLen);
bool allocate(size_t len);
bool addString(const char *data) { return addData(data, strlen(data)); }
bool addData(const char *data, size_t dataLen);
char *getBuffer() const { return buffer; }
size_t getOffset() const { return offset; }
size_t getBufferLen() const { return bufferLen; }
void clear();
protected:
char *buffer;
size_t bufferLen;
size_t offset;
bool staticBuffers;
};
class JsonReference;
/**
* API to the JsonParser
*
* This is a memory-efficient JSON parser based on jsmn. It only keeps one copy of the data in raw format
* and an array of tokens. You make calls to read values out.
*/
class JsonParser : public JsonBuffer {
public:
JsonParser();
virtual ~JsonParser();
/**
* Static buffers constructor
*/
JsonParser(char *buffer, size_t bufferLen, JsonParserGeneratorRK::jsmntok_t *tokens, size_t maxTokens);
/**
* Optional: Allocates the specified number of tokens. You should set this larger than the expected number
* of tokens for efficiency, but if you are not using the static allocator it will resize the
* token storage space if it's too small.
*/
bool allocateTokens(size_t maxTokens);
/**
* Parses the data you have added using addData() or addString().
*/
bool parse();
/**
*
*/
JsonReference getReference() const;
/**
* Typically JSON will contain an object that contains values and possibly other objects.
* This method gets the token for the outer object.
*/
const JsonParserGeneratorRK::jsmntok_t *getOuterObject() const;
/**
* Sometimes the JSON will contain an array of values (or objects) instead of starting with
* an object. This gets the outermost array.
*/
const JsonParserGeneratorRK::jsmntok_t *getOuterArray() const;
/**
* Gets the outer token, whether it's an array or object
*/
const JsonParserGeneratorRK::jsmntok_t *getOuterToken() const;
/**
* Given a token for an JSON array in arrayContainer, gets the number of elements in the array.
*
* 0 = no elements, 1 = one element, ...
*
* The index values for getValueByIndex(), etc. are 0-based, so the last index you pass in is
* less than getArraySize().
*/
size_t getArraySize(const JsonParserGeneratorRK::jsmntok_t *arrayContainer) const;
/**
* Given an object token in container, gets the value with the specified key name.
*
* This should only be used for things like string, numbers, booleans, etc.. If you want to get a JSON array
* or object within an object, use getValueTokenByKey() instead.
*/
template<class T>
bool getValueByKey(const JsonParserGeneratorRK::jsmntok_t *container, const char *name, T &result) const {
const JsonParserGeneratorRK::jsmntok_t *value;
if (getValueTokenByKey(container, name, value)) {
return getTokenValue(value, result);
}
else {
return false;
}
}
/**
* Gets the value with the specified key name out of the outer object
*
* This should only be used for things like string, numbers, booleans, etc.. If you want to get a JSON array
* or object within an object, use getValueTokenByKey() instead.
*/
template<class T>
bool getOuterValueByKey(const char *name, T &result) const {
const JsonParserGeneratorRK::jsmntok_t *value;
if (getValueTokenByKey(getOuterObject(), name, value)) {
return getTokenValue(value, result);
}
else {
return false;
}
}
/**
* Given an array token in arrayContainer, gets the value with the specified index.
*
* This should only be used for things like string, numbers, booleans, etc.. If you want to get a JSON array
* or object within an array, use getValueTokenByIndex() instead.
*/
template<class T>
bool getValueByIndex(const JsonParserGeneratorRK::jsmntok_t *arrayContainer, size_t index, T &result) const {
const JsonParserGeneratorRK::jsmntok_t *value;
if (getValueTokenByIndex(arrayContainer, index, value)) {
return getTokenValue(value, result);
}
else {
return false;
}
}
/**
* This method is used to extract data from a 2-dimensional JSON array, an array of arrays of values.
*
* This should only be used for things like string, numbers, booleans, etc.. If you want to get a JSON array
* or object within a two-dimensional array, use getValueTokenByColRow() instead.
*/
template<class T>
bool getValueByColRow(const JsonParserGeneratorRK::jsmntok_t *arrayContainer, size_t col, size_t row, T &result) const {
const JsonParserGeneratorRK::jsmntok_t *value;
if (getValueTokenByColRow(arrayContainer, col, row, value)) {
return getTokenValue(value, result);
}
else {
return false;
}
}
/**
* Given an object token in container, gets the token value with the specified key name.
*
* This can be used for objects whose keys are arrays or objects, to get the token for the container. It can
* also be used for values, but normally you'd use getValueByKey() instead, which is generally more convenient.
*/
bool getValueTokenByKey(const JsonParserGeneratorRK::jsmntok_t *container, const char *key, const JsonParserGeneratorRK::jsmntok_t *&value) const;
/**
* Given an array token in container, gets the token value with the specified index.
*
* This can be used for arrays whose values are arrays or objects, to get the token for the container. It can
* also be used for values, but normally you'd use getValueByIndex() instead, which is generally more convenient.
*/
bool getValueTokenByIndex(const JsonParserGeneratorRK::jsmntok_t *container, size_t desiredIndex, const JsonParserGeneratorRK::jsmntok_t *&value) const;
/**
* This method is used to extract data from a 2-dimensional JSON array, an array of arrays of values.
*
* This can be used for 2-dimensional arrays whose values are arrays or objects, to get the token for the container. It can
* also be used for values, but normally you'd use getValueByColRow() instead, which is generally more convenient.
*/
bool getValueTokenByColRow(const JsonParserGeneratorRK::jsmntok_t *container, size_t col, size_t row, const JsonParserGeneratorRK::jsmntok_t *&value) const;
/**
* Given a containing object, finds the nth token in the object
*/
const JsonParserGeneratorRK::jsmntok_t *getTokenByIndex(const JsonParserGeneratorRK::jsmntok_t *container, size_t desiredIndex) const;
/**
* Given a JSON object in container, gets the key/value pair specified by index.
*
* This is a low-level function; you will typically use getValueByIndex() or getValueByKey() instead.
*/
bool getKeyValueTokenByIndex(const JsonParserGeneratorRK::jsmntok_t *container, const JsonParserGeneratorRK::jsmntok_t *&key, const JsonParserGeneratorRK::jsmntok_t *&value, size_t index) const;
/**
* Used internally to skip over the token in obj.
*
* For simple primitives and strings, this is equivalent to obj++. For objects and arrays,
* however, this skips over the entire object or array, including any nested objects within
* them.
*/
bool skipObject(const JsonParserGeneratorRK::jsmntok_t *container, const JsonParserGeneratorRK::jsmntok_t *&obj) const;
/**
* Copies the value of the token into a buffer, making it a null-terminated cstring.
*
* If the string is longer than dstLen - 1 bytes, it will be truncated and the result will
* still be a valid cstring.
*
* This is used internally because the token data is not null-terminated, and doing
* things like sscanf or strtoul on it can read past the end of the buffer. This assures
* that only null-terminated data is passed to these functions.
*/
void copyTokenValue(const JsonParserGeneratorRK::jsmntok_t *token, char *dst, size_t dstLen) const;
/**
* Gets a bool (boolean) value.
*
* Normally you'd use getValueByKey(), getValueByIndex() or getValueByColRow() which will automatically
* use this when the result parameter is a bool variable.
*/
bool getTokenValue(const JsonParserGeneratorRK::jsmntok_t *token, bool &result) const;
/**
* Gets an integer value.
*
* Normally you'd use getValueByKey(), getValueByIndex() or getValueByColRow() which will automatically
* use this when the result parameter is an int variable.
*/
bool getTokenValue(const JsonParserGeneratorRK::jsmntok_t *token, int &result) const;
/**
* Gets an unsigned long value.
*
* Normally you'd use getValueByKey(), getValueByIndex() or getValueByColRow() which will automatically
* use this when the result parameter is an unsigned long variable.
*/
bool getTokenValue(const JsonParserGeneratorRK::jsmntok_t *token, unsigned long &result) const;
/**
* Gets a float (single precision floating point) value.
*
* Normally you'd use getValueByKey(), getValueByIndex() or getValueByColRow() which will automatically
* use this when the result parameter is a float variable.
*/
bool getTokenValue(const JsonParserGeneratorRK::jsmntok_t *token, float &result) const;
/**
* Gets a double (double precision floating point) value.
*
* Normally you'd use getValueByKey(), getValueByIndex() or getValueByColRow() which will automatically
* use this when the result parameter is a double variable.
*/
bool getTokenValue(const JsonParserGeneratorRK::jsmntok_t *token, double &result) const;
/**
* Gets a String value. This will automatically decode Unicode character escapes in the data and the
* returned String will contain UTF-8.
*
* Normally you'd use getValueByKey(), getValueByIndex() or getValueByColRow() which will automatically
* use this when the result parameter is a String variable.
*/
bool getTokenValue(const JsonParserGeneratorRK::jsmntok_t *token, String &result) const;
/**
* Gets a string as a cstring into the specified buffer. If the token specifies too large of a string
* it will be truncated. This will automatically decode Unicode character escapes in the data and the
* returned string will contain UTF-8.
*/
bool getTokenValue(const JsonParserGeneratorRK::jsmntok_t *token, char *str, size_t &strLen) const;
/**
* Gets a string as a JsonParserString object. This is used internally by getTokenValue() overloads
* that take a String or buffer and length; you will normally not need to use this directly.
*
* This will automatically decode Unicode character escapes in the data and the
* returned string will contain UTF-8.
*/
bool getTokenValue(const JsonParserGeneratorRK::jsmntok_t *token, JsonParserString &str) const;
/**
* Given a Unicode UTF-16 code point, converts it to UTF-8 and appends it to str.
*/
static void appendUtf8(uint16_t unicode, JsonParserString &str);
protected:
JsonParserGeneratorRK::jsmntok_t *tokens;
JsonParserGeneratorRK::jsmntok_t *tokensEnd;
size_t maxTokens;
JsonParserGeneratorRK::jsmn_parser parser;
};
/**
* Creates a JsonParser with a static buffer. You normally use this when you're creating a parser
* as a global variable.
*/
template <size_t BUFFER_SIZE, size_t MAX_TOKENS>
class JsonParserStatic : public JsonParser {
public:
explicit JsonParserStatic() : JsonParser(staticBuffer, BUFFER_SIZE, staticTokens, MAX_TOKENS) {};
private:
char staticBuffer[BUFFER_SIZE];
JsonParserGeneratorRK::jsmntok_t staticTokens[MAX_TOKENS];
};
/**
* Class for containing a reference to a JSON object, array, or value token
*
* This provides a fluent-style API for easily traversing a tree of JSON objects to find a value
*/
class JsonReference {
public:
JsonReference(const JsonParser *parser);
virtual ~JsonReference();
JsonReference(const JsonParser *parser, const JsonParserGeneratorRK::jsmntok_t *token);
JsonReference key(const char *name) const;
JsonReference index(size_t index) const ;
size_t size() const;
template<class T>
bool value(T &result) const {
if (token && parser->getTokenValue(token, result)) {
return true;
}
else {
return false;
}
}
bool valueBool(bool defaultValue = false) const;
int valueInt(int defaultValue = 0) const;
unsigned long valueUnsignedLong(unsigned long defaultValue = 0) const;
float valueFloat(float defaultValue = 0) const;
double valueDouble(double defaultValue = 0) const;
String valueString() const;
private:
const JsonParser *parser;
const JsonParserGeneratorRK::jsmntok_t *token;
};
typedef struct {
bool isFirst;
char terminator;
} JsonWriterContext;
/**
* Class for building a JSON string
*/
class JsonWriter : public JsonBuffer {
public:
JsonWriter();
virtual ~JsonWriter();
JsonWriter(char *buffer, size_t bufferLen);
/**
* You do not need to call init() as it's called from the two constructors. You can call it again
* if you want to reset the writer and reuse it, such as when you use JsonWriterStatic in a global
* variable.
*/
void init();
/**
*
*/
bool startObject() { return startObjectOrArray('{', '}'); };
bool startArray() { return startObjectOrArray('[', ']'); };
void finishObjectOrArray();
/**
* Inserts a boolean value ("true" or "false").
*
* You would normally use insertKeyValue() or insertArrayValue() instead of calling this directly
* as those functions take care of inserting the separtators between items.
*/
void insertValue(bool value);
/**
* Inserts an integer value.
*
* You would normally use insertKeyValue() or insertArrayValue() instead of calling this directly
* as those functions take care of inserting the separators between items.
*/
void insertValue(int value) { insertsprintf("%d", value); }
/**
* Inserts an unsigned integer value.
*
* You would normally use insertKeyValue() or insertArrayValue() instead of calling this directly
* as those functions take care of inserting the separators between items.
*/
void insertValue(unsigned int value) { insertsprintf("%u", value); }
/**
* Inserts a long integer value.
*
* You would normally use insertKeyValue() or insertArrayValue() instead of calling this directly
* as those functions take care of inserting the separators between items.
*/
void insertValue(long value) { insertsprintf("%ld", value); }
/**
* Inserts an unsigned long integer value.
*
* You would normally use insertKeyValue() or insertArrayValue() instead of calling this directly
* as those functions take care of inserting the separators between items.
*/
void insertValue(unsigned long value) { insertsprintf("%lu", value); }
/**
* Inserts a floating point value.
*
* Use setFloatPlaces() to set the number of decimal places to include.
*
* You would normally use insertKeyValue() or insertArrayValue() instead of calling this directly
* as those functions take care of inserting the separtators between items.
*/
void insertValue(float value);
/**
* Inserts a floating point double value.
*
* Use setFloatPlaces() to set the number of decimal places to include.
*
* You would normally use insertKeyValue() or insertArrayValue() instead of calling this directly
* as those functions take care of inserting the separtators between items.
*/
void insertValue(double value);
/**
* Inserts a quoted string value. This escapes special characters and encodes utf-8.
*
* You would normally use insertKeyValue() or insertArrayValue() instead of calling this directly
* as those functions take care of inserting the separtators between items.
*/
void insertValue(const char *value) { insertString(value, true); }
/**
* Inserts a quoted string value. This escapes special characters and encodes utf-8.
* See also the version that takes a plain const char *.
*
* You would normally use insertKeyValue() or insertArrayValue() instead of calling this directly
* as those functions take care of inserting the separtators between items.
*/
void insertValue(const String &value) { insertString(value.c_str(), true); }
/**
* Inserts a new key and empty object. You must close the object using finishObjectOrArray()!
*/
void insertKeyObject(const char *key);
/**
* Inserts a new key and empty array. You must close the object using finishObjectOrArray()!
*/
void insertKeyArray(const char *key);
/**
* Inserts a key/value pair into an object.
*
* Uses templates so you can pass any type object that's supported by insertValue() overloads,
* for example: bool, int, float, double, const char *.
*/
template<class T>
void insertKeyValue(const char *key, T value) {
insertCheckSeparator();
insertValue(key);
insertChar(':');
insertValue(value);
}
/**
* Inserts a value into an array.
*
* Uses templates so you can pass any type object that's supported by insertValue() overloads,
* for example: bool, int, float, double, const char *.
*/
template<class T>
void insertArrayValue(T value) {
insertCheckSeparator();
insertValue(value);
}
/**
* If you try to insert more data than will fit in the buffer, the isTruncated flag will be
* set, and the buffer will likely not be valid JSON and should not be used.
*/
bool isTruncated() const { return truncated; }
/**
* Sets the number of digits for formatting float and double values. Set it to -1 to use the
* default for snprintf.
*/
void setFloatPlaces(int floatPlaces) { this->floatPlaces = floatPlaces; }
/**
* Check to see if a separator needs to be inserted. You normally don't need to use this
* as it's called by insertKeyValue() and insertArrayValue().
*/
void insertCheckSeparator();
/**
* Used internally; you should use startObject() or startArray() instead.
* Make sure you finish any started object or array using finishObjectOrArray().
*/
bool startObjectOrArray(char startChar, char endChar);
/**
* Used internally. You should use insertKeyValue() or insertArrayValue() with a string instead.
*/
void insertChar(char ch);
/**
* Used internally. You should use insertKeyValue() or insertArrayValue() with a string instead.
*/
void insertString(const char *s, bool quoted = false);
/**
* Used internally. You should use insertKeyValue() or insertArrayValue() with a string, float, or
* double instead.
*
* This method does not quote or escape the string - it's used mainly for formatting numbers.
*/
void insertsprintf(const char *fmt, ...);
/**
* Used internally. You should use insertKeyValue() or insertArrayValue() with a string, float, or
* double instead.
*
* This method does not quote or escape the string - it's used mainly for formatting numbers.
*/
void insertvsprintf(const char *fmt, va_list ap);
/**
* This constant is the maximum number of nested objects that are supported; the actual number is
* one less than this so when set to 5 you can have four objects nested in each other.
*/
static const size_t MAX_NESTED_CONTEXT = 5;
protected:
size_t contextIndex;
JsonWriterContext context[MAX_NESTED_CONTEXT];
bool truncated;
int floatPlaces;
};
/**
* Creates a JsonWriter with a statically allocated buffer. You typically do this when you want
* to create a buffer as a global variable.
*/
template <size_t BUFFER_SIZE>
class JsonWriterStatic : public JsonWriter {
public:
explicit JsonWriterStatic() : JsonWriter(staticBuffer, BUFFER_SIZE) {};
private:
char staticBuffer[BUFFER_SIZE];
};
class JsonWriterAutoObject {
public:
JsonWriterAutoObject(JsonWriter *jw) : jw(jw) {
jw->startObject();
}
~JsonWriterAutoObject() {
jw->finishObjectOrArray();
}
protected:
JsonWriter *jw;
};
class JsonWriterAutoArray {
public:
JsonWriterAutoArray(JsonWriter *jw) : jw(jw) {
jw->startArray();
}
~JsonWriterAutoArray() {
jw->finishObjectOrArray();
}
protected:
JsonWriter *jw;
};
#endif /* __JSONPARSERGENERATORRK_H *///file name: JsonParserGeneratorRK.cpp
#include "Particle.h"
#include "JsonParserGeneratorRK.h"
JsonBuffer::JsonBuffer() : buffer(0), bufferLen(0), offset(0), staticBuffers(false) {
}
JsonBuffer::~JsonBuffer() {
if (!staticBuffers && buffer) {
free(buffer);
}
}
JsonBuffer::JsonBuffer(char *buffer, size_t bufferLen) : buffer(buffer), bufferLen(bufferLen), offset(0), staticBuffers(true) {
}
bool JsonBuffer::allocate(size_t len) {
if (!staticBuffers) {
char *newBuffer;
if (buffer) {
newBuffer = (char *) realloc(buffer, len);
}
else {
newBuffer = (char *) malloc(len);
}
if (newBuffer) {
buffer = newBuffer;
bufferLen = len;
return true;
}
else {
return false;
}
}
else {
return false;
}
}
bool JsonBuffer::addData(const char *data, size_t dataLen) {
if (!buffer || (offset + dataLen) > bufferLen) {
// Need to allocate more space for data
if (!allocate(offset + dataLen)) {
return false;
}
}
memcpy(&buffer[offset], data, dataLen);
offset += dataLen;
return true;
}
void JsonBuffer::clear() {
offset = 0;
}
//
JsonParser::JsonParser() : JsonBuffer(), tokens(0), maxTokens(0) {
}
JsonParser::JsonParser(char *buffer, size_t bufferLen, JsonParserGeneratorRK::jsmntok_t *tokens, size_t maxTokens) :
JsonBuffer(buffer, bufferLen), tokens(tokens), maxTokens(maxTokens) {
}
JsonParser::~JsonParser() {
if (!staticBuffers && tokens) {
free(tokens);
}
}
bool JsonParser::allocateTokens(size_t maxTokens) {
if (!staticBuffers) {
JsonParserGeneratorRK::jsmntok_t *newTokens;
if (tokens) {
newTokens = (JsonParserGeneratorRK::jsmntok_t *)realloc(buffer, sizeof(JsonParserGeneratorRK::jsmntok_t) * maxTokens);
}
else {
newTokens = (JsonParserGeneratorRK::jsmntok_t *)malloc(sizeof(JsonParserGeneratorRK::jsmntok_t) * maxTokens);
}
if (newTokens) {
tokens = newTokens;
this->maxTokens = maxTokens;
return true;
}
else {
return false;
}
}
else {
return false;
}
}
bool JsonParser::parse() {
if (tokens) {
// Try to use the existing token buffer if possible
JsonParserGeneratorRK::jsmn_init(&parser);
int result = JsonParserGeneratorRK::jsmn_parse(&parser, buffer, offset, tokens, maxTokens);
if (result == JsonParserGeneratorRK::JSMN_ERROR_NOMEM) {
if (staticBuffers) {
// If using static buffers and there is not enough space, fail
return false;
}
free(tokens);
tokens = 0;
maxTokens = 0;
}
else
if (result < 0) {
// Failed to parse: JSMN_ERROR_INVAL or JSMN_ERROR_PART
return false;
}
else {
tokensEnd = &tokens[result];
return true;
}
}
// Pass 1: determine now many tokens we need
JsonParserGeneratorRK::jsmn_init(&parser);
int result = JsonParserGeneratorRK::jsmn_parse(&parser, buffer, offset, 0, 0);
if (result < 0) {
// Failed to parse: JSMN_ERROR_INVAL or JSMN_ERROR_PART
return false;
}
// If we get here, tokens will always be == 0; it would have been freed if it was
// too small, and this code is never executed for staticBuffers == true
maxTokens = (size_t) result;
if (maxTokens > 0) {
tokens = (JsonParserGeneratorRK::jsmntok_t *)malloc(sizeof(JsonParserGeneratorRK::jsmntok_t) * maxTokens);
JsonParserGeneratorRK::jsmn_init(&parser);
int result = JsonParserGeneratorRK::jsmn_parse(&parser, buffer, offset, tokens, maxTokens);
tokensEnd = &tokens[result];
}
else {
tokensEnd = tokens;
}
/*
for(const JsonParserGeneratorRK::jsmntok_t *token = tokens; token < tokensEnd; token++) {
printf("%d, %d, %d, %d\n", token->type, token->start, token->end, token->size);
}
*/
return true;
}
JsonReference JsonParser::getReference() const {
if (tokens < tokensEnd) {
return JsonReference(this, &tokens[0]);
}
else {
return JsonReference(this);
}
}
const JsonParserGeneratorRK::jsmntok_t *JsonParser::getOuterArray() const {
for(const JsonParserGeneratorRK::jsmntok_t *token = tokens; token < tokensEnd; token++) {
if (token->type == JsonParserGeneratorRK::JSMN_ARRAY) {
return token;
}
}
return 0;
}
const JsonParserGeneratorRK::jsmntok_t *JsonParser::getTokenByIndex(const JsonParserGeneratorRK::jsmntok_t *container, size_t desiredIndex) const {
size_t index = 0;
const JsonParserGeneratorRK::jsmntok_t *token = container + 1;
while(token < tokensEnd && token->end < container->end) {
if (desiredIndex == index) {
return token;
}
index++;
skipObject(container, token);
}
return 0;
}
const JsonParserGeneratorRK::jsmntok_t *JsonParser::getOuterObject() const {
if (tokens < tokensEnd && tokens[0].type == JsonParserGeneratorRK::JSMN_OBJECT) {
return &tokens[0];
}
else {
return 0;
}
}
const JsonParserGeneratorRK::jsmntok_t *JsonParser::getOuterToken() const {
for(const JsonParserGeneratorRK::jsmntok_t *token = tokens; token < tokensEnd; token++) {
if (token->type == JsonParserGeneratorRK::JSMN_OBJECT || token->type == JsonParserGeneratorRK::JSMN_ARRAY) {
return token;
}
}
return 0;
}
bool JsonParser::skipObject(const JsonParserGeneratorRK::jsmntok_t *container, const JsonParserGeneratorRK::jsmntok_t *&obj) const {
int curObjectEnd = obj->end;
while(++obj < tokensEnd && obj->end < container->end && obj->end <= curObjectEnd) {
}
if (obj >= tokensEnd || obj->end > container->end) {
// No object after index
return false;
}
return true;
}
bool JsonParser::getKeyValueTokenByIndex(const JsonParserGeneratorRK::jsmntok_t *container, const JsonParserGeneratorRK::jsmntok_t *&key, const JsonParserGeneratorRK::jsmntok_t *&value, size_t desiredIndex) const {
size_t index = 0;
const JsonParserGeneratorRK::jsmntok_t *token = container + 1;
while(token < tokensEnd && token->end < container->end) {
if (desiredIndex == index) {
key = token;
if (skipObject(container, token)) {
value = token;
return true;
}
}
index++;
skipObject(container, token);
skipObject(container, token);
}
return false;
}
bool JsonParser::getValueTokenByKey(const JsonParserGeneratorRK::jsmntok_t *container, const char *name, const JsonParserGeneratorRK::jsmntok_t *&value) const {
const JsonParserGeneratorRK::jsmntok_t *key;
String keyName;
for(size_t ii = 0; getKeyValueTokenByIndex(container, key, value, ii); ii++) {
if (getTokenValue(key, keyName) && keyName == name) {
return true;
}
}
return false;
}
bool JsonParser::getValueTokenByIndex(const JsonParserGeneratorRK::jsmntok_t *container, size_t desiredIndex, const JsonParserGeneratorRK::jsmntok_t *&value) const {
size_t index = 0;
const JsonParserGeneratorRK::jsmntok_t *token = container + 1;
while(token < tokensEnd && token->end < container->end) {
if (desiredIndex == index) {
value = token;
return true;
}
index++;
skipObject(container, token);
}
return false;
}
bool JsonParser::getValueTokenByColRow(const JsonParserGeneratorRK::jsmntok_t *container, size_t col, size_t row, const JsonParserGeneratorRK::jsmntok_t *&value) const {
const JsonParserGeneratorRK::jsmntok_t *columnContainer;
if (getValueTokenByIndex(container, col, columnContainer)) {
return getValueTokenByIndex(columnContainer, row, value);
}
else {
return false;
}
}
size_t JsonParser::getArraySize(const JsonParserGeneratorRK::jsmntok_t *arrayContainer) const {
size_t index = 0;
const JsonParserGeneratorRK::jsmntok_t *token = arrayContainer + 1;
while(token < tokensEnd && token->end < arrayContainer->end) {
index++;
skipObject(arrayContainer, token);
}
return index;
}
void JsonParser::copyTokenValue(const JsonParserGeneratorRK::jsmntok_t *token, char *dst, size_t dstLen) const {
int ii;
for(ii = 0; ii < (token->end - token->start) && ii < ((int)dstLen - 1); ii++) {
dst[ii] = buffer[token->start + ii];
}
dst[ii] = 0;
}
bool JsonParser::getTokenValue(const JsonParserGeneratorRK::jsmntok_t *token, bool &result) const {
if (token->end > token->start) {
switch(buffer[token->start]) {
case 't': // should be this
case 'T':
case 'y':
case 'Y':
case '1':
result = true;
break;
default:
result = false;
break;
}
return true;
}
else {
return false;
}
}
bool JsonParser::getTokenValue(const JsonParserGeneratorRK::jsmntok_t *token, int &result) const {
// Copy data here, because tokens are not null terminated
char tmp[16];
copyTokenValue(token, tmp, sizeof(tmp));
if (sscanf(tmp, "%d", &result) == 1) {
return true;
}
else {
return false;
}
}
bool JsonParser::getTokenValue(const JsonParserGeneratorRK::jsmntok_t *token, unsigned long &result) const {
// Copy data here, because tokens are not null terminated
char tmp[16];
copyTokenValue(token, tmp, sizeof(tmp));
if (sscanf(tmp, "%lu", &result) == 1) {
return true;
}
else {
return false;
}
}
bool JsonParser::getTokenValue(const JsonParserGeneratorRK::jsmntok_t *token, float &result) const {
// Copy data here, because tokens are not null terminated
char tmp[16];
copyTokenValue(token, tmp, sizeof(tmp));
result = strtof(tmp, 0);
return true;
}
bool JsonParser::getTokenValue(const JsonParserGeneratorRK::jsmntok_t *token, double &result) const {
// Copy data here, because tokens are not null terminated
char tmp[16];
copyTokenValue(token, tmp, sizeof(tmp));
result = strtod(tmp, 0);
return true;
}
bool JsonParser::getTokenValue(const JsonParserGeneratorRK::jsmntok_t *token, String &result) const {
result = "";
result.reserve(token->end - token->start + 1);
JsonParserString strWrapper(&result);
return getTokenValue(token, strWrapper);
}
bool JsonParser::getTokenValue(const JsonParserGeneratorRK::jsmntok_t *token, char *str, size_t &bufLen) const {
JsonParserString strWrapper(str, bufLen);
bool result = getTokenValue(token, strWrapper);
bufLen = strWrapper.getLength() + 1;
return result;
}
bool JsonParser::getTokenValue(const JsonParserGeneratorRK::jsmntok_t *token, JsonParserString &str) const {
int unicode;
bool escape = false;
for(int ii = token->start; ii < token->end; ii++) {
if (escape) {
escape = false;
switch(buffer[ii]) {
case 'b':
str.append('\b');
break;
case 'f':
str.append('\f');
break;
case 'n':
str.append('\n');
break;
case 'r':
str.append('\r');
break;
case 't':
str.append('\t');
break;
case 'u':
if ((ii + 4) < token->end) {
// Copy data here because buffer is not null terminated and this could
// read past the end otherwise
char tmp[5];
for(size_t jj = 0; jj < 4; jj++) {
tmp[jj] = buffer[ii + jj + 1];
}
tmp[4] = 0;
if (sscanf(tmp, "%04x", &unicode) == 1) {
appendUtf8((uint16_t)unicode, str);
ii += 5; // also increments in loop
}
}
break;
default:
str.append(buffer[ii]);
break;
}
}
else
if (buffer[ii] == '\\') {
escape = true;
}
else {
str.append(buffer[ii]);
}
}
return true;
}
// [static]
void JsonParser::appendUtf8(uint16_t unicode, JsonParserString &str) {
unsigned char value;
if (unicode <= 0x007f) {
// 0x00000000 - 0x0000007F:
str.append((char)unicode);
}
else
if (unicode <= 0x7ff) {
// 0x00000080 - 0x000007FF:
// 110xxxxx 10xxxxxx
value = (0b11000000 | ((unicode >> 6) & 0b11111));
str.append((char)value);
value = (0b10000000 | (unicode & 0b111111));
str.append((char)value);
}
else {
// 0x00000800 - 0x0000FFFF:
// 1110xxxx 10xxxxxx 10xxxxxx
value = 0b11100000 | ((unicode >> 12) & 0b1111);
str.append((char)value);
value = 0b10000000 | ((unicode >> 6) & 0b111111);
str.append((char)value);
value = 0b10000000 | (unicode & 0b111111);
str.append((char)value);
}
}
//
//
//
JsonReference::JsonReference(const JsonParser *parser) : parser(parser), token(0) {
}
JsonReference::~JsonReference() {
}
JsonReference::JsonReference(const JsonParser *parser, const JsonParserGeneratorRK::jsmntok_t *token) : parser(parser), token(token) {
}
JsonReference JsonReference::key(const char *name) const {
const JsonParserGeneratorRK::jsmntok_t *newToken;
if (token && parser->getValueTokenByKey(token, name, newToken)) {
return JsonReference(parser, newToken);
}
else {
return JsonReference(parser);
}
}
JsonReference JsonReference::index(size_t index) const {
const JsonParserGeneratorRK::jsmntok_t *newToken;
if (token && parser->getValueTokenByIndex(token, index, newToken)) {
return JsonReference(parser, newToken);
}
else {
return JsonReference(parser);
}
}
size_t JsonReference::size() const {
if (token) {
return parser->getArraySize(token);
}
else {
return 0;
}
}
bool JsonReference::valueBool(bool result) const {
(void) value(result);
return result;
}
int JsonReference::valueInt(int result) const {
(void) value(result);
return result;
}
unsigned long JsonReference::valueUnsignedLong(unsigned long result) const {
(void) value(result);
return result;
}
float JsonReference::valueFloat(float result) const {
(void) value(result);
return result;
}
double JsonReference::valueDouble(double result) const {
(void) value(result);
return result;
}
String JsonReference::valueString() const {
String result;
(void) value(result);
return result;
}
//
//
//
JsonParserString::JsonParserString(String *str) : str(str), buf(0), bufLen(0), length(0){
}
JsonParserString::JsonParserString(char *buf, size_t bufLen) : str(0), buf(buf), bufLen(bufLen), length(0){
if (buf && bufLen) {
memset(buf, 0, bufLen);
}
}
void JsonParserString::append(char ch) {
if (str) {
str->concat(ch);
length++;
}
else {
if (buf && length < (bufLen - 1)) {
buf[length] = ch;
}
length++;
}
}
//
//
//
JsonWriter::JsonWriter() : JsonBuffer(), floatPlaces(-1) {
init();
}
JsonWriter::~JsonWriter() {
}
JsonWriter::JsonWriter(char *buffer, size_t bufferLen) : JsonBuffer(buffer, bufferLen), floatPlaces(-1) {
init();
}
void JsonWriter::init() {
// Save start of insertion point for later
offset = 0;
contextIndex = 0;
context[contextIndex].isFirst = false;
context[contextIndex].terminator = 0;
truncated = false;
}
bool JsonWriter::startObjectOrArray(char startChar, char endChar) {
if ((contextIndex + 1) >= MAX_NESTED_CONTEXT) {
return false;
}
contextIndex++;
context[contextIndex].isFirst = true;
context[contextIndex].terminator = endChar;
insertChar(startChar);
return true;
}
void JsonWriter::finishObjectOrArray() {
if (contextIndex > 0) {
if (context[contextIndex].terminator != 0) {
insertChar(context[contextIndex].terminator);
}
contextIndex--;
}
}
void JsonWriter::insertChar(char ch) {
if (offset < bufferLen) {
buffer[offset++] = ch;
}
else {
truncated = true;
}
}
void JsonWriter::insertString(const char *s, bool quoted) {
// 0x00000000 - 0x0000007F:
// 0x00000080 - 0x000007FF:
// 110xxxxx 10xxxxxx
// 0x00000800 - 0x0000FFFF:
// 1110xxxx 10xxxxxx 10xxxxxx
if (quoted) {
insertChar('"');
}
for(size_t ii = 0; s[ii] && offset < bufferLen; ii++) {
if (s[ii] & 0x80) {
// High bit set: convert UTF-8 to JSON Unicode escape
if (((s[ii] & 0b11110000) == 0b11100000) && ((s[ii+1] & 0b11000000) == 0b10000000) && ((s[ii+2] & 0b11000000) == 0b10000000)) {
// 3-byte
uint16_t utf16 = ((s[ii] & 0b1111) << 12) | ((s[ii+1] & 0b111111) << 6) | (s[ii+2] & 0b111111);
insertsprintf("\\u%04X", utf16);
ii += 2; // plus one more in loop increment
}
else
if (((s[ii] & 0b11100000) == 0b11000000) && ((s[ii+1] & 0b11000000) == 0b10000000)) {
// 2-byte
uint16_t utf16 = ((s[ii] & 0b11111) << 6) | (s[ii+1] & 0b111111);
insertsprintf("\\u%04X", utf16);
ii++; // plus one more in loop increment
}
else {
// Not valid unicode, just pass characters through
insertChar(s[ii]);
}
}
else {
switch(s[ii]) {
case '\b':
insertChar('\\');
insertChar('b');
break;
case '\f':
insertChar('\\');
insertChar('f');
break;
case '\n':
insertChar('\\');
insertChar('n');
break;
case '\r':
insertChar('\\');
insertChar('r');
break;
case '\t':
insertChar('\\');
insertChar('t');
break;
case '"':
case '\\':
insertChar('\\');
insertChar(s[ii]);
break;
default:
insertChar(s[ii]);
break;
}
}
}
if (quoted) {
insertChar('"');
}
}
void JsonWriter::insertsprintf(const char *fmt, ...) {
va_list ap;
va_start(ap, fmt);
insertvsprintf(fmt, ap);
va_end(ap);
}
void JsonWriter::insertvsprintf(const char *fmt, va_list ap) {
size_t spaceAvailable = bufferLen - offset;
size_t count = vsnprintf(&buffer[offset], spaceAvailable, fmt, ap);
if (count <= spaceAvailable) {
offset += count;
}
else {
// Truncated, no more space left
offset = bufferLen;
truncated = true;
}
}
void JsonWriter::insertCheckSeparator() {
if (context[contextIndex].isFirst) {
context[contextIndex].isFirst = false;
}
else {
insertChar(',');
}
}
void JsonWriter::insertValue(bool value) {
if (value) {
insertString("true");
}
else {
insertString("false");
}
}
void JsonWriter::insertValue(float value) {
if (floatPlaces >= 0) {
insertsprintf("%.*f", floatPlaces, value);
}
else {
insertsprintf("%f", value);
}
}
void JsonWriter::insertValue(double value) {
if (floatPlaces >= 0) {
insertsprintf("%.*lf", floatPlaces, value);
}
else {
insertsprintf("%lf", value);
}
}
void JsonWriter::insertKeyObject(const char *key) {
insertCheckSeparator();
insertValue(key);
insertChar(':');
startObject();
}
void JsonWriter::insertKeyArray(const char *key) {
insertCheckSeparator();
insertValue(key);
insertChar(':');
startArray();
}
// begin jsmn.cpp
// https://github.com/zserge/jsmn
namespace JsonParserGeneratorRK {
/**
* Allocates a fresh unused token from the token pull.
*/
static jsmntok_t *jsmn_alloc_token(jsmn_parser *parser,
jsmntok_t *tokens, size_t num_tokens) {
jsmntok_t *tok;
if (parser->toknext >= num_tokens) {
return NULL;
}
tok = &tokens[parser->toknext++];
tok->start = tok->end = -1;
tok->size = 0;
#ifdef JSMN_PARENT_LINKS
tok->parent = -1;
#endif
return tok;
}
/**
* Fills token type and boundaries.
*/
static void jsmn_fill_token(jsmntok_t *token, jsmntype_t type,
int start, int end) {
token->type = type;
token->start = start;
token->end = end;
token->size = 0;
}
/**
* Fills next available token with JSON primitive.
*/
static int jsmn_parse_primitive(jsmn_parser *parser, const char *js,
size_t len, jsmntok_t *tokens, size_t num_tokens) {
jsmntok_t *token;
int start;
start = parser->pos;
for (; parser->pos < len && js[parser->pos] != '\0'; parser->pos++) {
switch (js[parser->pos]) {
#ifndef JSMN_STRICT
/* In strict mode primitive must be followed by "," or "}" or "]" */
case ':':
#endif
case '\t' : case '\r' : case '\n' : case ' ' :
case ',' : case ']' : case '}' :
goto found;
}
if (js[parser->pos] < 32 || js[parser->pos] >= 127) {
parser->pos = start;
return JSMN_ERROR_INVAL;
}
}
#ifdef JSMN_STRICT
/* In strict mode primitive must be followed by a comma/object/array */
parser->pos = start;
return JSMN_ERROR_PART;
#endif
found:
if (tokens == NULL) {
parser->pos--;
return 0;
}
token = jsmn_alloc_token(parser, tokens, num_tokens);
if (token == NULL) {
parser->pos = start;
return JSMN_ERROR_NOMEM;
}
jsmn_fill_token(token, JSMN_PRIMITIVE, start, parser->pos);
#ifdef JSMN_PARENT_LINKS
token->parent = parser->toksuper;
#endif
parser->pos--;
return 0;
}
/**
* Fills next token with JSON string.
*/
static int jsmn_parse_string(jsmn_parser *parser, const char *js,
size_t len, jsmntok_t *tokens, size_t num_tokens) {
jsmntok_t *token;
int start = parser->pos;
parser->pos++;
/* Skip starting quote */
for (; parser->pos < len && js[parser->pos] != '\0'; parser->pos++) {
char c = js[parser->pos];
/* Quote: end of string */
if (c == '\"') {
if (tokens == NULL) {
return 0;
}
token = jsmn_alloc_token(parser, tokens, num_tokens);
if (token == NULL) {
parser->pos = start;
return JSMN_ERROR_NOMEM;
}
jsmn_fill_token(token, JSMN_STRING, start+1, parser->pos);
#ifdef JSMN_PARENT_LINKS
token->parent = parser->toksuper;
#endif
return 0;
}
/* Backslash: Quoted symbol expected */
if (c == '\\' && parser->pos + 1 < len) {
int i;
parser->pos++;
switch (js[parser->pos]) {
/* Allowed escaped symbols */
case '\"': case '/' : case '\\' : case 'b' :
case 'f' : case 'r' : case 'n' : case 't' :
break;
/* Allows escaped symbol \uXXXX */
case 'u':
parser->pos++;
for(i = 0; i < 4 && parser->pos < len && js[parser->pos] != '\0'; i++) {
/* If it isn't a hex character we have an error */
if(!((js[parser->pos] >= 48 && js[parser->pos] <= 57) || /* 0-9 */
(js[parser->pos] >= 65 && js[parser->pos] <= 70) || /* A-F */
(js[parser->pos] >= 97 && js[parser->pos] <= 102))) { /* a-f */
parser->pos = start;
return JSMN_ERROR_INVAL;
}
parser->pos++;
}
parser->pos--;
break;
/* Unexpected symbol */
default:
parser->pos = start;
return JSMN_ERROR_INVAL;
}
}
}
parser->pos = start;
return JSMN_ERROR_PART;
}
/**
* Parse JSON string and fill tokens.
*/
int jsmn_parse(jsmn_parser *parser, const char *js, size_t len,
jsmntok_t *tokens, unsigned int num_tokens) {
int r;
int i;
jsmntok_t *token;
int count = parser->toknext;
for (; parser->pos < len && js[parser->pos] != '\0'; parser->pos++) {
char c;
jsmntype_t type;
c = js[parser->pos];
switch (c) {
case '{': case '[':
count++;
if (tokens == NULL) {
break;
}
token = jsmn_alloc_token(parser, tokens, num_tokens);
if (token == NULL)
return JSMN_ERROR_NOMEM;
if (parser->toksuper != -1) {
tokens[parser->toksuper].size++;
#ifdef JSMN_PARENT_LINKS
token->parent = parser->toksuper;
#endif
}
token->type = (c == '{' ? JSMN_OBJECT : JSMN_ARRAY);
token->start = parser->pos;
parser->toksuper = parser->toknext - 1;
break;
case '}': case ']':
if (tokens == NULL)
break;
type = (c == '}' ? JSMN_OBJECT : JSMN_ARRAY);
#ifdef JSMN_PARENT_LINKS
if (parser->toknext < 1) {
return JSMN_ERROR_INVAL;
}
token = &tokens[parser->toknext - 1];
for (;;) {
if (token->start != -1 && token->end == -1) {
if (token->type != type) {
return JSMN_ERROR_INVAL;
}
token->end = parser->pos + 1;
parser->toksuper = token->parent;
break;
}
if (token->parent == -1) {
if(token->type != type || parser->toksuper == -1) {
return JSMN_ERROR_INVAL;
}
break;
}
token = &tokens[token->parent];
}
#else
for (i = parser->toknext - 1; i >= 0; i--) {
token = &tokens[i];
if (token->start != -1 && token->end == -1) {
if (token->type != type) {
return JSMN_ERROR_INVAL;
}
parser->toksuper = -1;
token->end = parser->pos + 1;
break;
}
}
/* Error if unmatched closing bracket */
if (i == -1) return JSMN_ERROR_INVAL;
for (; i >= 0; i--) {
token = &tokens[i];
if (token->start != -1 && token->end == -1) {
parser->toksuper = i;
break;
}
}
#endif
break;
case '\"':
r = jsmn_parse_string(parser, js, len, tokens, num_tokens);
if (r < 0) return r;
count++;
if (parser->toksuper != -1 && tokens != NULL)
tokens[parser->toksuper].size++;
break;
case '\t' : case '\r' : case '\n' : case ' ':
break;
case ':':
parser->toksuper = parser->toknext - 1;
break;
case ',':
if (tokens != NULL && parser->toksuper != -1 &&
tokens[parser->toksuper].type != JSMN_ARRAY &&
tokens[parser->toksuper].type != JSMN_OBJECT) {
#ifdef JSMN_PARENT_LINKS
parser->toksuper = tokens[parser->toksuper].parent;
#else
for (i = parser->toknext - 1; i >= 0; i--) {
if (tokens[i].type == JSMN_ARRAY || tokens[i].type == JSMN_OBJECT) {
if (tokens[i].start != -1 && tokens[i].end == -1) {
parser->toksuper = i;
break;
}
}
}
#endif
}
break;
#ifdef JSMN_STRICT
/* In strict mode primitives are: numbers and booleans */
case '-': case '0': case '1' : case '2': case '3' : case '4':
case '5': case '6': case '7' : case '8': case '9':
case 't': case 'f': case 'n' :
/* And they must not be keys of the object */
if (tokens != NULL && parser->toksuper != -1) {
jsmntok_t *t = &tokens[parser->toksuper];
if (t->type == JSMN_OBJECT ||
(t->type == JSMN_STRING && t->size != 0)) {
return JSMN_ERROR_INVAL;
}
}
#else
/* In non-strict mode every unquoted value is a primitive */
default:
#endif
r = jsmn_parse_primitive(parser, js, len, tokens, num_tokens);
if (r < 0) return r;
count++;
if (parser->toksuper != -1 && tokens != NULL)
tokens[parser->toksuper].size++;
break;
#ifdef JSMN_STRICT
/* Unexpected char in strict mode */
default:
return JSMN_ERROR_INVAL;
#endif
}
}
if (tokens != NULL) {
for (i = parser->toknext - 1; i >= 0; i--) {
/* Unmatched opened object or array */
if (tokens[i].start != -1 && tokens[i].end == -1) {
return JSMN_ERROR_PART;
}
}
}
return count;
}
/**
* Creates a new parser based over a given buffer with an array of tokens
* available.
*/
void jsmn_init(jsmn_parser *parser) {
parser->pos = 0;
parser->toknext = 0;
parser->toksuper = -1;
}
}
// end jsmn.cpp












Share this Project
Found In
Courses
49713 Designing for the Internet of Things
· 25 members
A hands-on introductory course exploring the Internet of Things and connected product experiences.
Focused on
Skills
Tools
About
This project is an classical style Bus Reminder. It can showcase all or selected bus at the specific stop by LED bubble. When a bus is going to come to the bus stop, the LED bubble which represents it will be lighted up. Every bubble represents a coming bus in its 5 min time span.
Created
January 24th, 2018